Document Tracking System
Published at: 2025-08-20
Last Modified: 2025-08-23
Introduction
A comprehensive document tracking solution designed to digitize and streamline the flow of physical documents across departments within organizations. This system provides transparent tracking of document routing, processing status, approval workflows, and complete audit trails. With features like due date management, and multi-user authorization levels, it offers both functionality and modern UI/UX that accommodates traditional workflows while embracing contemporary application standards.
Technologies Used
The Document Tracking System (DTS) is a full-stack web application consisting primarily of web technologies.
Frontend
- HTML (yes! pure HTML)
- JavaScript
- Bootstrap - CSS framework
- select2 - Searchable dropdown menus
- summernote - Rich WYSIWYG Editor for
textarea
Backend
- Bun - Faster JS runtime for servers
- Hono - API Library
- Drizzle - ORM for database
- SQLite - Main database
- Redis - Session Authentication Database
- Nodemailer - SMTP Transporter
- Caddy - Web Server
- TypeScript
Development Environment
- Visual Studio Code & Dev Containers
- Docker
- Live Server VSCode Extension and its browser extension counterpart
- Ethereal.email - Fake SMTP Service
- Figma - Design Mockups
Production Environment
- Docker
- Cloudflare Tunnels
Core Inspiration
This project was developed as a final project for my COMP 016 WEB DEVELOPMENT course. The task was to create a prototype web application, that is fully functioning (why prototype then?) and it will be presented one month after it was announced.
Our group was tasked with a Document Tracking System. At first thought, you would think that it is a courier service for personal documents but it wasn’t. What our professor meant by Document Tracking System was akin to the university’s own Document Tracking System where the goal is to digitize the way documents are sent or received within the organization.
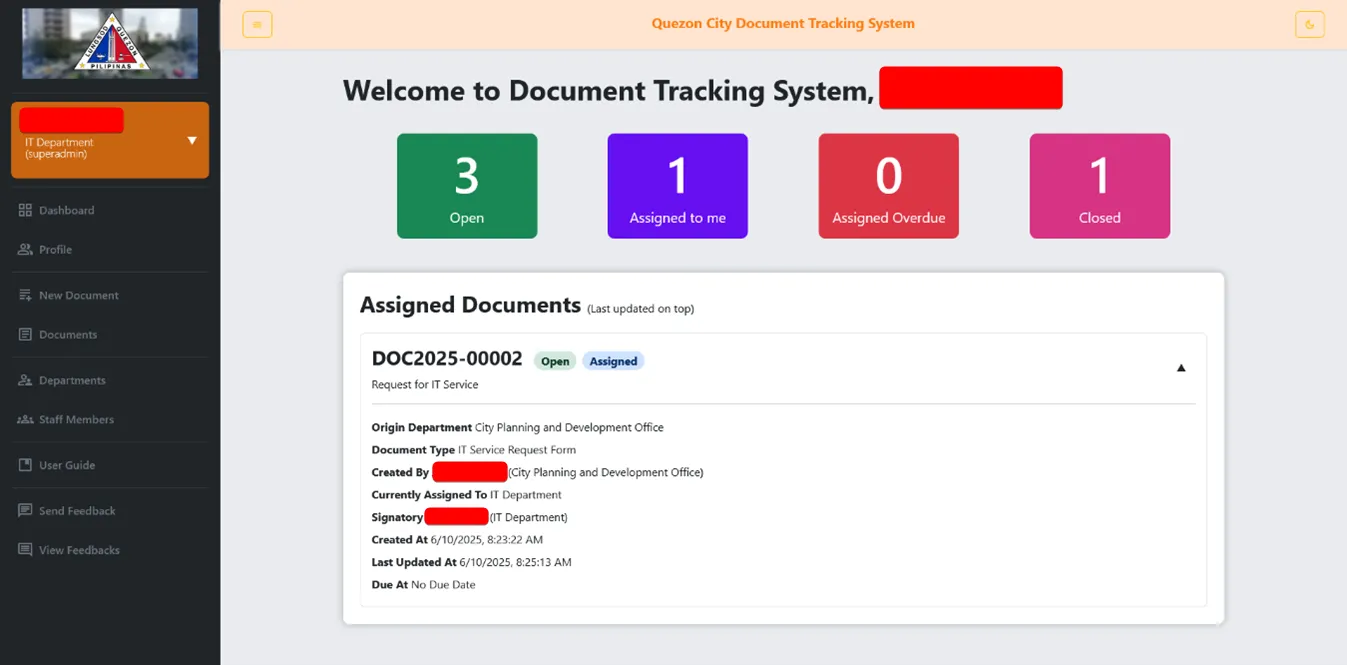
What does the Document Tracking System do?
Document Tracking System is a platform for internal departments of an organization to track physical documents they release or receive across the organization. It is a transparent way to see where and who processed/transported the document to someone.
Visually it is represented like this:
IT Employee 1 -> IT Department Clerk -> HR Department Clerk -> HR Employee 1 -> Approved -> Return to IT Employee 1
Quite complicated, isn’t it?
DTS Features
Beyond the simple description of “It tracks documents”, here are the overview of its features.
- Dashboard showing
Open,Closed,Assigned to me,Overdue Assigned to meDocuments - Document Aging
- Document Logs / Audit Trails
- Document Filtering and Search
- Department and Staff List Pages
- Multi-role authorization
- Automated Forgot Password Process
The Development Process
The project started around third week of May 2025 with planning on what to do. We started with a Figma design that is quite similar to the university’s internal tool.
The First Commit
We settled with HTML, Bootstrap, JavaScript as the primary technologies we would use in the front-end. On the backend side, I pushed through with TypeScript as I am familiar with it, but this time I am using the hot new JS runtime, Bun.
Bun is a new JavaScript runtime built from scratch to serve the modern JavaScript ecosystem. It has three major design goals: Speed, Elegant APIs, and Cohesive DX. — Bun
It is actually a classic move for me to use different technologies I am interested with in every projects I make.
The first commit has been pushed to origin/main on May 27.
- Commit 2a1a45a -
init project
This commit consists of several files, mainly minified Bootstrap JS and CSS files, index.html and dashboard.html.
and also the .gitignore as always
Backend’s Role
The backend heavily handles the logic and coordination behind the scenes. We went with Bun as the TypeScript Runtime because it promised that it is faster than Node.js. We also went with SQLite, and Redis for databases, and we used Drizzle as our ORM to interface the SQLite database.
The SQLite main database houses everything from user accounts, up until the document logs. It somehow manage to do these hefty stuff up. I initially planned to migrate to MySQL at some point however, due to some constraits in migrating the Drizzle codebase to use MySQL, it would mean that I had to rewrite the Drizzle table objects into MySQL meaning more work to do. So I let it be.
I need REST(ful APIs)
In this application, we are going to use REST API principles, JSON as the transport method, and Hono as the library to handle the API. Express.js is also a candidate since I have used it before but since we are going with the Bun runtime, I think its better to learn some libraries native to Bun as well.
The migration from Express.js to Hono is not that big, and you could transfer some Express.js conventions to Hono. However the big differences between the two are how tight-knit Hono is to full Type-Safety.
Back in Express.js, you could separate routes, controllers, logic to other files by using the router and somehow connect them from bottom to the most top router.
To better visualize these, here’s a route and logic file that I used to do in Express:
// routes/index.route.ts
const router = Rotuer()
router.post("/:id", AuthMiddleware, postRouterController)
export default router;
// controllers/index/postRouter.controller.ts
export const postRouterController: RequestHandler = async (req, res, next) = {
const { id } = req.params; // only inferred as [key: string]: unknown
// doesn't know it actually exists
// logic here
}
This is fine for the most part but one misspell can turn the whole code base down with hard time to find out where it went wrong.
Hono in the other hand doesn’t recommend this Ruby on Rails pattern. Instead they recommend you, at most, to just put every logic in a route in one file. That way, some middlewares or dynamic routing won’t be lost in logic.
Using the same idea, I would rewrite the code above into Hono:
// routes/index.route.ts
const indexRouter = new Hono();
indexRouter.post("/:id", AuthMiddleware, async (c) => {
const { id } = c.req.param(); // knows it actually exists
// inferred as a string.
// logic here
});
export default indexRouter; // will be used in main `/api` router
Though this will result in lengthy code later on, It ensures that type-safety is always there while you are developing.
Authentication police here! Present your Session Cookies now!
This is also the first time I’m using Redis as well as the concept of Session Cookies. Back then I used to put every identifiable information inside a JWT token but apparently it might a bad idea to do so.
In this project, I used Redis as a quick database to sort out my Session Authentication solution.
Back in the front-end, it is coded to request to /api/check with its cookies every single time a page loads or refreshes. This ensures that the user will be able to access protected resources without signing in everytime.
This cookie handles a session id that will be checked against the Redis database and if it exists and valid, the user can continue what they are doing.
Redis is also my storage for forgot password tokens because it has Time-to-live (TTL) feature for its key-pair values. This ensures that after a specific time, Redis will automatically delete the key-pair value. Very useful in session and forgot password tokens indeed.
The Hurdles, and the Solutions
In every project, there’s always hurdles that will come through. It could be from poor decision-making or limitation of the technology itself. Though as there are always hurdles, there’s always solutions to it… or resorting to live with this limitation.
1. Restricting myself to just HTML and JS
When I said that it is running pure HTML and JS (in the front-end), I mean it. The whole front-end component are just HTML and JS.
Now what are the problems along with this decision. Let me list those:
- No reusability of ‘components’
- No framework I could offload work too (I might become too dependent on frameworks)
- No App Router
Of course its just HTML what did you expect? My fear of PHP has come to this decision.
Ok, so what are the benefits along with this decision:
- No compilation
yeah… I think I pushed the difficulty bar too high.
Now that’s been done, I manage to push through just by living with it. Manually copy pasting the Navigation bar on every page sigh. Some components like a custom dropdown with a search bar and a Rich WYSIWYG editor are done using jQuery and its vast plugin ecosystem. I’ve never though I’m using jQuery ever but here it is.
2. Custom Routing without JS Framework’s Aid
Up until this point, I don’t really know how or what is Routing is fully. The last time I did routing was a Vue SPA project with Vue router as its routing. I’ve learned there that you could do routing, and error pages which are really cool. But this time around, I don’t have the luxury of frameworks. This is the part where Caddy comes in.
Like nginx, Caddy is a web server and a reverse-proxy where it hosts files to somewhere. With a pure HTML stack, you don’t really expect to have 404 pages, custom slugs in the URL, and being able to strip out .html at the end of the URL.
With the help of Caddy and its extensive configuration, I managed to do all of that.
:80 {
root * /srv/
rewrite /documents/* document.html
rewrite /departments/* department.html
@stripExtensions path_regexp strip (.*)\.(html)
redir @stripExtensions {re.strip.1} 301
try_files {path} {path}/ {path}.html
# try_files {path}.html
file_server {
hide .git
}
reverse_proxy /api/* http://dts-server:54321
handle_errors {
@404 {
expression {http.error.status_code} == 404
}
rewrite @404 notfound.html
file_server {
hide .git
}
}
log {
output file /var/log/caddy/site.log
}
}
Explaining from top to bottom briefly, everything is served to the port :80 and it will turn into some port defined in the docker-compose.yml.
Some rewrite methods there are to redirect a wildcard of urls into the specific html file. For example, /documents/1 -> document.html
Then, in document.page.js, we would try to get the id by getting the current pathname and get the last part. As simple as that
function getTrackingNumberFromUrl() {
const urlParts = window.location.pathname.split("/");
return urlParts[urlParts.length - 1];
}
@stripExtensions is a custom directive that would regex out the .html extension
handle_errors is the error handling of caddy where I pointed 404 status code to notfound.html
Beyond this implementation with Caddy, I also have some sneaky redirection technique found in index.page.js where everytime I load into the domain, I would either go to the login page, or proceed directly to dashboard.
(async () => {
try {
const res = await fetch(`${API_URL}/api/check`, { credentials: "include" });
const redirected = statusRedirect(res, "replace");
if (!redirected) redirect("/dashboard", "replace");
} catch (e) {
console.error(e);
}
})();
const statusRedirect = (res, redirectType) => {
if (res.ok) return false;
switch (res.status) {
case 401:
redirect("/login", redirectType);
return true;
case 403:
redirect("/forbidden", redirectType);
return true;
case 404:
redirect("/notfound", redirectType);
return true;
case 500:
redirect("/servererror", redirectType);
return true;
default:
return false;
}
};
Afterword
135 commits after, the final commit (Commit e9ec506 - updated pdf iframe height) has been pushed to origin/main at June 25, 2025, 1 month after the first commit.
Honestly, it was a wild ride because of my decision to introduce some challenge to a major project. My professor and the panelists praised the project and gave us a satisfactory grade of 1.25.
Because of this project, I’ve learned more about web servers and how HTML and JS harmoniously integrate with each other. Some of my JS code are too complicated because of type-checking but it could’ve been simplier, cleaner, and readable if I had the time to polish it more but it is what it is.
To effective learn, you must try to do a lot of projects, with some challenges to force yourself to learn from it. But do not stuck with it, The IT landscape are continously improving and we must move along with it. — chocomilku